2月10日晚9时,bat365在线平台“科研我当先”实践团队线上进行第九次内容分享。会议由曹博文同学主持,全体成员参加。
在本次线上交流中,曹博文关于围棋AI中的AlphaGo整体算法进行了深入浅出的分享 。首先曹博文简单讲解了深度卷积神经网络(DCNN)的核心思想。之后,他介绍了Deepmind团队基于DCNN实现的四个“大脑”:SL.Policy Network(监督学习策略网络)RL.Policy Network(强化学习策略网络),Rollout(随机模拟走子),Vaue Network(价值网络)。
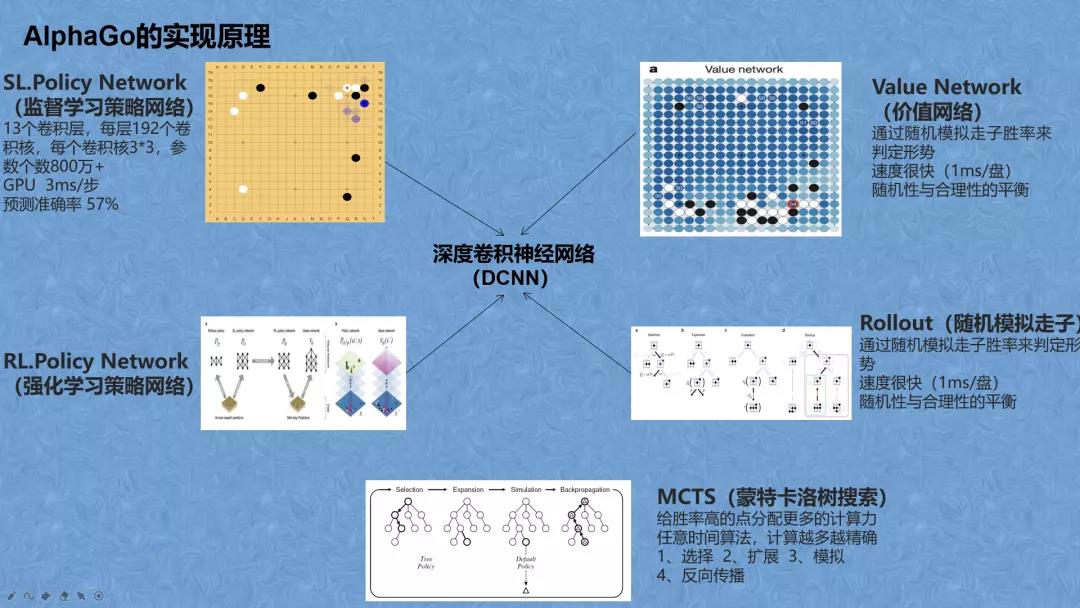
接着,曹博文通过与传统博弈游戏树搜索算法--极大极小搜索进行对比,点明了传统算法解决围棋问题的困难性,引出了AlphaGo整体算法的框架,也是算法核心--蒙特卡洛树搜索。蒙特卡洛树搜索的主要概念是搜索,即沿着博弈树向下的一组遍历过程。单次遍历的路径会从根节点(当前博弈状态)延伸到没有完全展开的节点,未完全展开的节点表示其子节点至少有一个未访问到。遇到未完全展开的节点时,它的一个未访问子节点将会作为单次模拟的根节点,随后模拟的结果将会反向传播回当前树的根节点并更新博弈树的节点统计数据。一旦搜索受限于时间或计算力而终止,下一步行动将基于收集到的统计数据进行决策。他通过对蒙特卡洛树算法原理的讲解,带着大家完整地体会了一遍AlphaGo算法的流程。
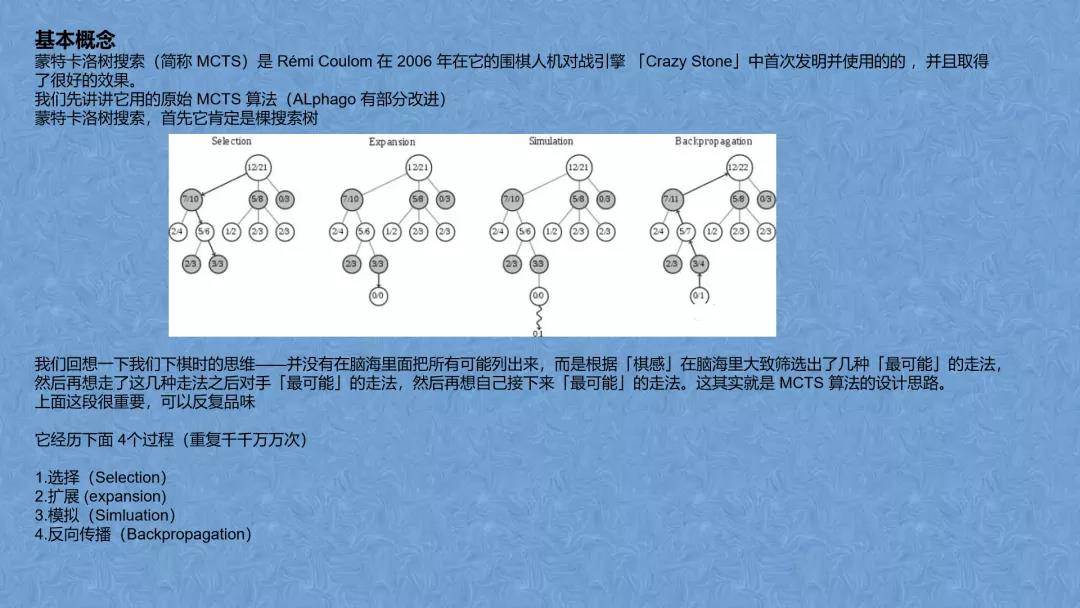
通过此次曹博文同学的分享,团队成员对AlphaGo的算法实现原理有了大致的了解,拓展了知识。本次会议分享持续了三十五分钟,对于非本专业的员工是一次很好的学习机会
(文/曹博文 图/毛潆晗)
